Abstract
Haskell and Standard ML are two popular functional programming languages with varying degrees of type safety and functional purity. Both languages have heralded type systems that implement compile-time static type checking with polymorphic types and pattern matching. Haskell forces the programmer to make safe decisions regarding side effects by providing mathematically-proven structures such as “monads” and enforcing complete variable immutability while Standard ML relaxes side effect management and allows mutable references which enable the programmer to think about their program with less overhead but inherently less safety guarantees than Haskell. Haskell’s syntax is more modern and readable than Standard ML’s syntax, but Standard ML provides some features such as polymorphic type inference that reduces the amount of code that clutters its definitions compared to Haskell. Haskell’s lazy expression evaluation is considered another hallmark of the language and has many advantages compared to Standard ML’s eagerly evaluated expressions by potentially reducing the amount of processing cycles that expressions consume. This makes Haskell suited for applications requiring fast parallel computing, but both languages are general-purpose languages and can be used to build a wide variety of applications using all the benefits of the functional language paradigm.
Introduction
To adequately assess the acceleration of functional programming concepts in modern-day programming, Haskell and Standard ML must be carefully inspected: how have these two somewhat-obscure languages erected an entire paradigm of computing? How do they relate and how do they differ? This paper compares Haskell and Standard ML and analyzes the readability, writability, and reliability of both languages. Each language also distinctly defines a strict type system that will be closely inspected. This paper assumes that the reader has some degree of familiarity with Standard ML.
Haskell and Standard ML both meet in the territory of functional programming. Functional programming is a paradigm of computing based on lambda calculus, a mathematical theory of abstract computational processes, and functional programming emphasizes strong types, immutability, and other unique features. Both languages provide general-purpose programming semantics suited for many categories of software development, and both are completely portable languages that compile on Windows, macOS, FreeBSD, and many other operating systems. Interestingly, both languages released their 1.0 version in 1990. Haskell gets its namesake from Haskell Curry, a mathematician known for his foundational work in combinatorics. The original Haskell founders developed the language out of frustration — nearly all functional languages at the time, the late 1980’s, tightly specialized their use to a specific class of programming problems; no useful general-purpose language existed that suited the founders’ intents. [10] Created by Peyton Jones, Paul Hudak, and a number of other members on the original Haskell Committee, Haskell supports general-purpose, high-level programming with a rigorous mathematical foundation. Haskell’s type system in particular gleans from an esoteric field of mathematics called “category theory” that has been hailed as one of the most powerful features of the language by introducing true functional composition. [1] Because of its strict functional nature, Haskell performs very well with multi-threaded applications. [35] The Standard ML committee, on the other hand, proposed a language particularly intended for “finding and performing proofs”. [9] Robin Milner, a professor at the University of Cambridge, standardized ML, which stands for “Meta Language”, as “an application of logical rigour to writing code”. [9] Because of this premise, Standard ML highly benefits language and grammar parsing applications as well as theorem-proving models.
Despite their similarities and notable benefits, Haskell is much more powerful and suited for more applications because of its purely functional nature and type system, but its strictness and typing concepts are much more difficult to comprehend than Standard ML.
This paper organizes its content into an Overview and Language Features section. The Overview section discusses the surface-level syntax and structure of each language and instructions on how to compile a program in Haskell. The Language Features section splits into multiple subsections that each discuss different key comparisons and interesting yet useful oddities of both languages; the categories of features discussed include types, variables, expressions, control statements, subroutines, and functional programming.
Overview
This section contrasts the syntactic and modular differences between Haskell and Standard ML through a detailed explanation of common language features and a walk-through of an example code listing. This section concludes with a detailed step-by-step process of how to compile and run a Haskell source file in Ubuntu Linux.
Structure and Syntax
Haskell organizes its programs into pure functions in one or more source files and shares those functions using modules. Modules collect the functions in a file into a unique name-space that can be imported by any other module in the program. [36] Standard ML, in contrast, has a much simpler import system that uses the use "<file>"; syntax to import the definitions from "<file>". Haskell defines a program’s entry point as the main function that has the IO monad type. A monad guarantees that a function remains pure despite side effects that it may produce, such as printing to a file stream; Haskell strictly enforces functional purity and technically defines no possible way of circumventing its purity checks. The Haskell standard library, called Prelude, supplies a wide array of utilities that eclipses Standard ML’s standard library. [6] Standard ML does not define an entry point and evaluates in-order similar to a scripting language.
Haskell implements an extensive operator set that includes basic arithmetic, logical and list operators, but it also includes functional operators like pattern matching and lambda operators. [37] Operators in Haskell can be used in normal infix-notation, 3 + 5, or they can be used as prefix-notation, (+) 3 5; this also applies for operators that normally apply with prefix notation which can be used as infix with backticks: (-) foldl 5. Most Haskell syntax can take these forms, formally known as the “sweet” and “unsweet” versions of the syntax. [5] “Point-free” style cleans up syntactic elements even further by automatically inferring function parameters to clarify function composition in the code. [7] Haskell statements use newlines as statement separators for nearly all expressions. [50] Therefore, since whitespace affects the interpretation of match and multi-line expressions, Haskell is not considered a free-form language. [4] Haskell variables and definitions are case-sensitive, and types and typeclasses must start with an uppercase first letter while functions and variables must start with a lowercase first letter. [8] Because of these naming conventions and Haskell’s method of pattern matching, functional polymorphism looks syntactically clearer than in Standard ML. Comments use the double-dash prefix ----: for example, ---- this is a Haskell comment.
select [] _ = []
select (x : xs) f =
(if f x then [x] else []) ++ (select xs f)
main = do
putStrLn "filter even or odd numbers?"
input <- getLine
if (input == "even") then do
print(select lst even)
else print(select lst odd)
where lst = [1,2,3,4,5,6,7,8,9,10]Figure 1: Sample program in Haskell
The listing in Figure 1 filters a list of the numbers 1 to 10 for even or odd numbers at the user’s request. Most developers can much more quickly comprehend this 10-line listing than Standard ML’s 30-line listing in Figure 2 (even though it is compacted for the sake of typesetting this paper). Line 1 matches an empty list and anything to an empty list; this is almost identical to the Standard ML listing. Line 2 matches a list starting with the element x and rest-of-list xs and a function f. Haskell’s pattern matching syntactically looks like a function redefinition, while Standard ML uses the pipe symbol | to separate pattern-matching function clauses. Line 3 states that if the function applied to x returns true, add x to the front of the list (++) and recursively select the tail of the list, xs. This statement is virtually identical to Standard ML’s version. Line 4 defines the main entry point with a do block that provides the IO monad features. In Standard ML, main has to be explicitly called at the end of the program because of its in-order evaluation. On Line 5, the program prints a message to the user. Standard ML’s version is similar but must specify the newline character. Haskell’s input stream mechanism on Line 6 is far superior to Standard ML’s enforced use of the Option type to read input. Line 7 tests for string equivalence; Standard ML concisely prefers pattern matching in many cases since the language’s string equality tests can be cumbersome. Line 8 then prints to stdout the result of calling select on the predefined list with the even function from the Prelude module. [6] Standard ML automatically prints the result of an expression evaluation to stdout. Haskell includes many utility functions similar to even, as seen on Line 9 which prints to stdout the result of calling select on the list with the odd function, which Prelude also contains. Standard ML does not have these utility functions and must be explicitly defined. Lastly, Line 10 defines local variables to be used in the where block, in this case the list to filter. Haskell uses where for monadic expressions and pattern guards and its scope binds to the entire function block. [38]
fun select [] _ = []
| select (x :: xs) f =
(if (f x) then [x] else [])
@ (select xs f);
fun printIntLst lst =
print ("[" ^
(foldr (fn (a,b) =>
(Int.toString a) ^ "," ^ b)
"" lst) ^ "]\n")
fun filterNums "even\n" lst =
printIntLst (select lst
(fn x => (x mod 2) = 0))
| filterNums _ lst
printIntLst (select lst
(fn x => ((x mod 2) = 1)));
fun main () =
let
val _ =
print "filter even or odd numbers?\n"
val inp = Option.getOpt
(TextIO.inputLine TextIO.stdIn,
"NONE")
in
filterNums inp [1,2,3,4,5,6,7,8,9,10]
end;
main ();Figure 2: Sample program in Standard ML
Language Processor
This paper uses the GHC Haskell compiler to compile and interactively interpret Haskell programs. [3] GHCup, the Haskell installation toolchain manager, maintains and easily provides the GHC binary and its toolset. [2] A Haskell program can either be loaded interactively using GHCi, ghci <program.hs>, or compiled using GHC, ghc --make <program.hs>. For example, to execute the program in Figure 1 in a shell as in Figure 3, first save the source code of the program into main.hs. Second, load the program interactively by entering $ ghci main.hs. Third, type and enter main at the Prelude> prompt to execute the main function. Lastly, enter a valid program input for the program to accordingly filter the list. Last, type and enter :quit at the Prelude> prompt to exit ghci and return to the shell.
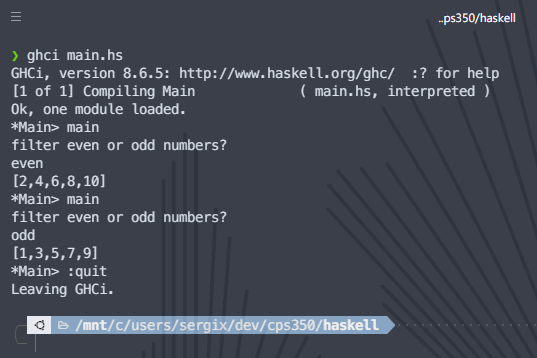
Figure 3: Sample program running in GHCI on WSL2.
Language Features
This section compares various language features common to both Haskell and Standard ML and analyzes their advantages and disadvantages through concrete examples. Each subsection evaluates individual components of a portion of the language definition.
Types
Haskell and Standard ML implement a strong typing system that enforces type strictness and static typing for all variables at compile-time to prevent errors. Haskell slightly simplifies typing syntax compared to Standard ML for types like tuples and polymorphic types, as seen in Figure 4 and Figure 5 and therefore has more readable types. Haskell’s compiler also helps writing programs by generating much clearer and more helpful messages for type errors than Standard ML. However, Haskell’s extensive type system can cause confusion of which type structure to use in which cases. [11] Lastly, Haskell provides a much more reliable and provable type system than Standard ML because of its strong mathematical foundation.
-- tuple type annotation
f :: (a, b) -> (a, b)
f x = x
-- polymorphic types
g :: a -> a
g x = xFigure 4: Type annotations in Haskell.
(* tuple type annotation *)
fun f (x: 'a * 'b) = x;
(* polymorphic types *)
fun g (x: 'a) = x;Figure 5: Type annotations in Standard ML.
Haskell resolves type comparisons by using nominal typing for algebraic types and structural typing for programmatically-defined type synonyms. [12] Standard ML, on the other hand, uses structural typing for all type comparisons by recursively determining the type’s dependents and comparing the fundamental requirements of both types. [39] Haskell’s typing definitions are much clearer and more concise than Standard ML’s definitions; for example, to define a polymorphic recursive type for a list in Haskell, the Haskell expression data List a = Nil | Cons a (List a) [48] semantically equates to the Standard ML expression datatype 'a list = nil | :: of 'a * 'a list. [49] The Haskell version uses more natural naming conventions for its type expressions than Standard ML and has a significant advantage in readability, which also gives Haskell a writeability advantage in constructing type declarations over Standard ML. However, since Haskell uses two different type comparison systems, it can be cumbersome to define structural types that enforce one method of type comparison over the other. [12] For example, as in Figure 6 when defining a type synonym using the type keyword, the Haskell language system compares the T_Point3 and T_Vector3 using structural typing and so they are equivalent types. However, when defined using the data keyword as for Point3 and Vector3, the type takes constructor arguments [46] and outputs a D_Point3 or D_Vector3 and subjects to nominal type comparisons, so therefore the types are not equivalent. Since all type comparisons in Standard ML use the same comparison system, its type system tends to be more reliable in terms of predictability, but Haskell’s more extensive structural typing system provides more functionality to the programmer.
-- structural equivalence
type T_Point3 = (Int, Int, Int)
type T_Vector3 = (Int, Int, Int)
-- name equivalence
data D_Point3 = Point3 Int Int Int
data D_Vector3 = Vector3 Int Int IntFigure 6: Type declarations in Haskell.
Both Haskell and Standard ML’s type system automatically infer types for expressions and variables. Type annotations for variables are optional in both languages, but they can be used to clarify or enforce a specific type and increase the readability of the code. (As an aside, Haskell’s operator for providing a type annotation, ::, can be easily confused with Standard ML’s syntax for the cons operator.) Haskell and Standard ML’s inferred types are useful and clear to the programmer and accurately determine the appropriate types for expressions. However, Haskell does not infer polymorphic types [22] and must be explicitly annotated [13], which decreases the writability of types in Haskell compared to Standard ML’s more intuitive system of inferring types from most general (polymorphic types) to specific (“ground” types, such as int) as it assesses the type of an expression. However, because Haskell does not infer polymorphic types, forcing the programmer to explicitly annotate polymorphic types does increase the reliability of the language since the compiler must statically check the explicitly defined type.
Before continuing, the notion of a monad must be clarified since they commonly appear in Haskell programs and will be mentioned later in this paper. A monad is another mathematical concept from category theory that obeys a set of abstract properties and “pipes” results from computations into other structures while enforcing type checks. [51] Monads can be reused and composed with functions and other sequential processes. Programs implement monads to “isolate” computations in functions with possible side effects into a separate construct to ensure that functions with side effects retain their purity. [51] A couple of familiar examples of built-in monads in Haskell are the Maybe and IO monads. [51]
Variables
Haskell’s variables are always immutable [23] while Standard ML’s variables are immutable by-default and provides mutable reference types. [14] Immutability in both languages makes code easier to reason about since you do not have to track when the state of a variable mutates, especially across large programs. However, Haskell and Standard ML’s immutability introduces more variables and prevents reusing a name for a value inside the same scope which potentially decreases the readability and writability of both languages since it can be cumbersome to propose new names for variables every time that a value mutates. Standard ML’s mutable references reuse blocks of memory pointed to by a variable and provide convenience for the programmer and increase the language’s writability. Standard ML reference variables are assigned using the := syntax and dereferenced using the !reference_var syntax. [14] However, despite its syntactic disadvantages, Haskell’s immutability increases reliability since it guarantees memory safety at the compiler level, especially with computing lists; on the other hand, this guarantee increases the computational overhead of mutating data structures during runtime.
Optional types stipulate the possibility of a value and provide mechanisms for interacting with the contained value. Both Haskell and Standard ML contribute optional type definitions that can be easily used in case expressions and with pattern matching [18], as seen in Figure 7. Haskell’s optional type syntax is more readable and natural than Standard ML’s, using the Maybe monad with Nothing and Just as the constructors, while Standard ML uses the option type with NONE and SOME. Haskell’s Maybe monad also inherits the equality and ordinance types, so equality-testing is built-in to Haskell’s Maybe definition [17] while Standard ML’s equality testing for option types must be explicitly defined using equality type variables, such as ''a option. [39] Therefore, Haskell’s optional types are more reliable and intuitive than Standard ML’s optional types because of the its built-in equality testing support.
-- outputs x's contained value if it holds a
-- value y, or False if no value is held
f :: Maybe Bool -> Bool
f x = case x of
Just y -> y
Nothing -> False
-- True
f (Just True)
-- False
f (Just False)
-- False
f (Nothing)Figure 7: Optional types in Haskell.
Expressions
Haskell and Standard ML implement most common logical and arithmetic operators, though Standard ML’s operators tend to be less syntactically conventional. Haskell’s boolean operators use the readable and well-known syntax && and ||, while Standard ML uses andalso and orelse, respectively. Haskell equivalence operators, ==, are also more conventional than Standard ML’s, =, since the single equal character can be confused with the assignment operator in most modern languages. Haskell and Standard ML’s do not differ semantically and the boolean operators short-circuit as expected, so the operators’ syntactic differences do not ultimately affect their writability. In addition, Haskell operators can be passed as parameters to functions by just passing the operator while operator functions in Standard ML can be passed by using the op keyword. Haskell “infix functions can also be partially applied by using sections” [19] by adding parentheses around the expression, as seen in Figure 8 [19], which makes the code slightly more writable than Standard ML since Standard ML does not implement this functionality.
-- explicit parameter with infix notation
divideByTen x = x / 10
-- explicit parameter with prefix notation
divideByTen x = (/) x 10
-- implicit parameter applied as first
-- division operand
divideByTen = (/10)Figure 8: Prefix and infix operator syntax in Haskell (from cited source). [19]
Haskell lazily evaluates expressions: the processor does not evaluate an expression until immediately needed in a computation. [24] On the other hand, Standard ML eagerly, or immediately, evaluates expressions, but lazy evaluation can manually be added to a Standard ML program. [25] Haskell uses lazy evaluation for every expression, which tends to consume more memory than eager evaluation in Standard ML and can decrease the reliability for programs that need to be memory-efficient. However, the Haskell compiler may optimize the program to not use lazy evaluation for specific expressions if it meets a compiler-defined case to consume less memory. [26] Standard ML’s eager evaluation, in contrast, may consume more processor cycles than needed but typically results in less memory usage. In conclusion, Haskell optimizes for processor cycles while Standard ML optimizes for memory usage and results in reliability concerns for the programmer in both languages.
Control Statements
If-else statement branches in both languages must evaluate to the same type since the entire statement is a single expression. This implies that if-else statements can be embedded into parentheses and inserted anywhere where it can be properly evaluated as an expression in the program. In addition, as shown in Figure 9, Haskell’s syntax provides more readable options than Standard ML since it provides optional syntactic sugar for if-else statements as pattern guards [21], which also makes the expressions more writable since the syntax translates from other familiar functional concepts.
-- normal if-then-else expression
isEven :: Int -> Bool
isEven number =
if number `mod` 2 == 0
then True
else False
-- pattern guards
isEven :: Int -> Bool
isEven number
| number `mod` 2 == 0 = True
| otherwise = FalseFigure 9: Comparing Haskell pattern guard syntax to if-then-else expression syntax.
In the Haskell language, errors are not exceptions: errors are represented by undefined and include infinite loops [29] and unhandled exceptions [28], while exceptions include I/O exceptions and other side effect exceptions. Standard ML defines the general Fail exception with specific exceptions for divide-by-zero (Div), nonexhuastive matches (Match), and other common exceptions. [30] Standard ML handles exceptions using the handle case expression in functions. [30] Haskell enforces the use of side effect handling through monads [27] which can result in cluttered and difficult-to-read exception handlers, but they can be implemented for a function by simply adding a type annotation. Both Haskell and Standard ML user-defined exceptions are just type definitions [47] [30], although Standard ML tends to be more writable since it more conventionally handles exceptions with a general exception type, as in Figure 10. Haskell’s added complexity, however, introduces more fluid possibilities for handling side effect exceptions, as seen in Figure 11. Because of Haskell’s strong and reliable typing system, though, Haskell rarely even needs to handle exceptions. [27] On the other hand, Standard ML greatly simplifies exception handling and therefore may be handled simpler by the programmer at the cost of less functionality.
exception HttpExceptionContent of int
exception StatusCodeException of string
exception TooManyRedirects of string
exception OverlongHeaders of int
exception ResponseTimeout of intFigure 10: Examples of Standard ML user-defined exception types.
data HttpExceptionContent
= StatusCodeException
(Response ()) S.ByteString
| TooManyRedirects [Response L.ByteString]
| OverlongHeaders
| ResponseTimeoutFigure 11: Examples of Haskell user-defined exception types (from cited source). [47]
Subroutines
Haskell and Standard ML have similar scoping and lifetime rules. In both languages, let expressions always define a lexical nested scope. Neither language’s scoping rules have any unusual quirks that affect readability since they both use the most local nested scope for bindings, except that Standard ML’s case statement “bindings are visible only inside the body of the rule”. [33] Similarly, although applied to functions, Haskell where clauses “scope bindings over several guarded equations” [32] in function pattern guards, as seen in Figure 12. Both languages are similarly reliable since they require consistent lexical scoping rules and variable lifetimes, and variable lifetimes do not necessarily apply to Haskell because its variables are immutable and functions bind to values.
f x y
| y > z = 0
| y == z = 1
| y < z = 2
where z = x * xFigure 12: Haskell where clause bindings over pattern guards (from cited source). [32]
Haskell uniquely restricts side effects to be handled by monads to ensure functional purity in its programs, while Standard ML allows side effects as a “mostly-pure” language. Haskell’s enforcement of monadic structures and other closures can clutter a program’s code and be less readable than Standard ML, especially with type definitions. This also affects Haskell’s side effect handling writability since the language may increase mental overhead in defining an appropriate monad or other functional construct, while Standard ML has a relaxed approach to handling side effects. Haskell’s monad instances require three main components, as seen in Figure 13 with the monad instance Maybe: a type definition, a binding for each possible value that “combines values of that type with computations” using the bind notation >>=, and a function called return that “takes a value and embeds it in the monad”. [51] Many modern programmers consider monads a notoriously difficult concept to grasp without much prior experience in functional programming because of their highly abstract nature. Despite the difficulties in reading and writing monads, Haskell’s refusal of side-effects reliably ensures state safety and encourages testable functions more than Standard ML since non-pure Standard ML functions may not be testable if it has print statements or other side effects.
-- Maybe type definition
data Maybe a = Just a | Nothing
-- formal definition of the Maybe monad
-- in Prelude
instance Monad Maybe where
-- value bindings
Nothing >>= f = Nothing
(Just x) >>= f = f x
-- build the Maybe monad when given
-- a value
return = Just
-- the Maybe type class can now be attached
-- to type signatures on subroutines
f :: Maybe x -> xFigure 13: Haskell Maybe type defined as an instance of a Monad (from cited source). [51]
Both languages encourage polymorphic programming through parametric polymorphism with type variables since parametric polymorphism works best with pattern-matched and recursive functional languages. Haskell’s polymorphic types are slightly more readable since they look like variable name bindings, such as a, while Standard ML adds the extra apostrophe 'a. Haskell’s polymorphic functions must be explicitly defined through type annotations (as previously discussed in the Types section) while Standard ML’s type inference system automatically generates polymorphic functions and makes them more easily writable than Haskell’s polymorphic functions. Furthermore, Haskell validates equality types by checking for an associated Eq typeclass in the parameter type [16], while Standard ML enforces equality type checking when defining a polymorphic function using equality type variables, such as ''a. In this case, Haskell polymorphic function definitions are more reliable than Standard ML’s since the Eq typeclasses are more powerful and flexible than Standard ML’s rigid equality type checking. Other subtypes can be applied to polymorphic parameters in Haskell to ensure type safety when applying functions to polymorphic parameters. [20]
Functional programming hails recursion as a critical component of its paradigm. Both languages strongly encourage recursion as opposed to iterative loops, although Standard ML provides while loops. [15] Programmers can easily identify base cases in recursive functions in both Haskell and Standard ML; however, Haskell’s ability to separate a function’s type annotation to its own line (to also provide parametric polymorphism) helps clarify immediately the input and output of each of a function’s recursive cases, which makes Haskell’s recursive functions — specifically for recursive polymorphic functions as in Figure 14 — slightly more understandable than Standard ML’s annotations, but it also clutters the syntax compared to the Standard ML version in Figure 15. Haskell and Standard ML have no syntactic differences in writing recursive functions as opposed to non-recursive functions. Furthermore, Haskell’s recursion model is more reliable than Standard ML’s model since it safely enforces looping via recursion while Standard ML’s while loops could cause unexpected exceptions due to out-of-bounds errors or other side effects.
sum :: (Num a) => [a] -> a
sum [] = 0
sum (x:xs) = x + sum xsFigure 14: Haskell recursive function with polymorphic types (from cited source). [20]
fun sum [] = 0
| sum (x::xs) = x + sum xs;Figure 15: The Haskell function in Figure 14 translated to Standard ML.
”Advanced” Feature
Most of this paper has discussed different key components of functional programming, and since Haskell is a purely functional language it includes some useful syntactic and semantic advantages. Lambda expressions in Haskell, as in Figure 16, use the backslash character with a binding name to define a lambda expression, and a lambda expression can also be applied by in-lining the lambda using parentheses. Lambda expressions are particularly used for function currying and with map, fold, and other list modification functions. [31] In addition, Haskell implements pattern matching, another constituent of functional programming, for functions and case expressions. Pattern matching matches a variable to a predefined pattern that binds values and simplifies polymorphic function invocation. Haskell also specially implements a lazy pattern that can be used to always match an expression [32] to delay type checking on values that are passed to functions. [52] Types with only one constructor use lazy patterns to delay computation to prevent exhaustive pattern matching checks so that its only pattern will immediately match all cases. [52] However, because lazy patterns defer type checking to the runtime, the compiler will not attempt to type-check the pattern, which could lead to unexpected runtime errors on erroneous matches. A lazy pattern simply prefixes the pattern with a tilde: ~pattern.
-- defining a lambda expression using the
-- binding name "y"
plusTwo = \y -> y + 2
-- applying a lambda expression inline
(\y -> y + 2) 2Figure 16: Lambda expressions in Haskell.
Conclusion
Haskell trumps Standard ML in many aspects of readability and writability with its required annotated types and syntactic sugar with more conventional and modern syntax than Standard ML. However, Standard ML’s flexible inferred types and simpler side effect handling reduces the amount of mental overhead of simple tasks such as printing to stdout. This becomes Haskell’s reliability advantage, though, since these strict language requirements guarantee type safety and robust exception prevention while Standard ML cannot provide these same guarantees.
Haskell’s purely functional nature results in applications well-suited for parallel programming but extends to any type of application since it is a general-purpose programming language. Haskell’s strictness far outweighs other functional languages, but many developers need this guaranteed safety for mission-critical applications in finance, engineering, and other sectors. [41]
Haskell use has declined over the past decade, to the point that some have called it a “dead” programming language [44], but a wide range of companies and industries still employ it today. [45] The language working group does not regularly make new announcements and has grown inactive: the last official meeting was in February 2021 [43], and the last official update to the Haskell Report (the Haskell language definition) was in 2010. [42] At the time of publication, Haskell currently ranks #39 on the TIOBE Index with a 0.21% usage rating among all programming languages. [40]
References
[1] https://en.wikibooks.org/wiki/Haskell/Category_theory
[2] https://www.haskell.org/ghcup/
[3] https://www.haskell.org/ghc/
[4] https://en.wikibooks.org/wiki/Haskell/Indentation
[5] https://en.wikibooks.org/wiki/Haskell/Syntactic_sugar
[6] https://hackage.haskell.org/package/base-4.17.0.0/docs/Prelude.html#v:even
[7] https://wiki.haskell.org/Pointfree
[8] https://wiki.haskell.org/Programming_guidelines
[9] Robert Milner, The Definition of Standard ML (Revised). MIT Press, 1997. ISBN 0-262-63181-4.
[10] Paul Hudak, A History of Haskell: Being Lazy With Class. ACM, Inc. DOI 10.1145/1238844.1238856.
[11] https://free.cofree.io/2020/09/01/type-errors/
[12] https://101wiki.softlang.org/Concept:Structural_typing
[13] https://wiki.haskell.org/Monomorphism_restriction
[14] https://homepages.inf.ed.ac.uk/mfourman/teaching/mlCourse/notes/sml-mutable-reference.html%5B.htm%5D
[15] https://homepages.inf.ed.ac.uk/stg/NOTES/node87.html
[16] https://andrew.gibiansky.com/blog/haskell/haskell-typeclasses/
[17] https://wiki.haskell.org/Maybe
[18] https://courses.cs.washington.edu/courses/cse341/04wi/lectures/08-ml-refs.html
[19] http://learnyouahaskell.com/higher-order-functions
[20] http://learnyouahaskell.com/syntax-in-functions
[21] https://en.wikibooks.org/wiki/Haskell/Control\_structures
[22] https://www.tweag.io/blog/2020-03-12-expl-spec/
[23] https://mmhaskell.com/blog/2017/1/9/immutability-is-awesome
[24] https://wiki.haskell.org/Lazy\_evaluation
[25] https://smlhelp.github.io/book/concepts/lazy.html
[26] https://wiki.haskell.org/Performance/Strictness
[27] https://wiki.haskell.org/Exception
[28] https://wiki.haskell.org/Error
[29] https://www.haskell.org/onlinereport/haskell2010/haskellch3.html#x8-230003.1
[30] https://smlhelp.github.io/book/concepts/exn.html
[31] https://wiki.haskell.org/Anonymous_function
[32] https://www.haskell.org/tutorial/patterns.html
[33] https://courses.cs.washington.edu/courses/cse341/04wi/lectures/05-ml-scoping.html
[34] https://smlhelp.github.io/book/concepts/poly.html
[35] https://donsbot.com/2010/06/01/open-source-bridge-talk-multicore-haskell-now/
[36] https://www.haskell.org/tutorial/modules.html
[37] https://github.com/haskellcats/haskell-operators
[38] https://wiki.haskell.org/Let_vs._Where
[39] http://mlton.org/PolymorphicEquality
[40] https://www.tiobe.com/tiobe-index/
[41] https://wiki.haskell.org/Introduction
[42] https://www.haskell.org/onlinereport/haskell2010/
[43] https://discourse.haskell.org/t/working-group-minutes/1779
[44] https://www.techtarget.com/searchapparchitecture/tip/5-dead-programming-languages-we-should-never-forget”
[45] https://wiki.haskell.org/Haskell_in_industry
[46] https://101wiki.softlang.org/Concept:Algebraic_data_type
[47] https://www.fpcomplete.com/blog/defining-exceptions-in-haskell/
[48] https://www.haskellforall.com/2021/02/
[49] https://homepages.inf.ed.ac.uk/stg/NOTES/node41.html
[50] https://www.fpcomplete.com/blog/2012/09/ten-things-you-should-know-about-haskell-syntax/
[51] https://wiki.haskell.org/All_About_Monads#What_is_a_monad.3F
[52] https://en.wikibooks.org/wiki/Haskell/Laziness